Trapheus

Restore RDS instances in AWS without worrying about client downtime or configuration retention.
Trapheus can restore individual RDS instance or a RDS cluster.
Modelled as a state machine, with the help of AWS step functions, Trapheus restores the RDS instance in a much faster way than the usual SQL dump preserving the same instance endpoint and confgurations as before.

![]()


![]() Anglais|Chinois simplifié|français
Anglais|Chinois simplifié|français
- Important:cette application utilise divers services AWS et des coûts sont associés à ces services après l’utilisation de l’offre gratuite - veuillez consulter lePage de tarification AWSpour plus de détails.
📖 Table of Contents
[](#table-of-contents) ## ➤ Table des matières - - [➤ Prérequis](#-pre-requisites) - - [➤ Paramètres](#-parameters) - - [➤ Instructions](#-instructions) - - [➤ Exécution](#-execution) - - [➤ Comment ça marche](#-how-it-works) - - [➤ Contribuer à Trapheus](#-contributing-to-trapheus) - - [➤ Contributeurs](#-contributors) - - [➤ Montrez votre soutien](#-show-your-support)

➤ Prérequis
L’application nécessite que les ressources AWS suivantes existent avant l’installation :
-
python3.11installé sur la machine locale suivantece. - ConfigurerAWS SES
- Configurez l’e-mail de l’expéditeur et du destinataire SES (SES Console->Adresses e-mail).
- Une alerte par courrier électronique SES est configurée pour informer l’utilisateur de toute défaillance de la machine à états. Le paramètre email de l’expéditeur est nécessaire pour configurer l’ID de messagerie via lequel l’alerte est envoyée. Le paramètre email du destinataire est nécessaire pour définir l’ID de messagerie auquel l’alerte est envoyée.
- Configurez l’e-mail de l’expéditeur et du destinataire SES (SES Console->Adresses e-mail).
- Créez le compartiment S3 dans lequel le système va stocker les modèles de formation de nuages :
- Nom proposé : trapheus-cfn-s3-[identifiant de compte-]-[région]. Il est recommandé que le nom contienne votre :
- identifiant de compte, car les noms de compartiment doivent être globaux (empêche quelqu’un d’autre d’avoir le même nom)
- région, pour suivre facilement lorsque vous avez des compartiments trapheus-s3 dans plusieurs régions
- Nom proposé : trapheus-cfn-s3-[identifiant de compte-]-[région]. Il est recommandé que le nom contienne votre :
- Un VPC (spécifique à la région). Le même VPC/région doit être utilisé à la fois pour la ou les instances RDS, à utiliser dans Trapheus, et pour les lambdas de Trapheus.
- Considération de sélection de région. Régions prenant en charge :
- Réception d’email. VérifierParamètres-> ‘RecipientEmail’ pour en savoir plus.
- Exemple de configuration minimale d’un VPC :
- Console VPC :
- nom : Trapheus-VPC-[région](spécifie le[région]où votre VPC est créé - pour suivre facilement lorsque vous avez des Trapheus-VPC dans plusieurs régions)
- Bloc CIDR IPv4: 10.0.0.0/16
- Console VPC->Page Sous-réseaux et créez deux sous-réseaux privés :
- Sous-réseau 1 :
- VPC : Trapheus-VPC-[région]
- Zone de disponibilité : choisissez-en une
- Bloc CIDR IPv4 : 10.0.0.0/19
- Sous-réseau2 :
- VPC : Trapheus-VPC-[région]
- Zone de disponibilité : choisissez-en une différente de celle du sous-réseau 1 AZ.
- Bloc CIDR IPv4 : 10.0.32.0/19
- Sous-réseau 1 :
- Vous avez créé un VPC avec seulement deux sous-réseaux privés. Si vous créez des sous-réseaux non privés, cochezle rapport entre les sous-réseaux privés et publics, le sous-réseau privé avec une liste de contrôle d’accès réseau personnalisée dédiée et la capacité de réserve.
- Console VPC :
- Considération de sélection de région. Régions prenant en charge :
- Une ou plusieurs instances d’une base de données RDS que vous souhaitez restaurer.
- Exemple minimal_gratuit_Configuration RDS :
- Options du moteur : MySQL
- Modèles : niveau gratuit
- Paramètres : entrez le mot de passe
- Connectivité : VPC : Trapheus-VPC-[région]
- Exemple minimal_gratuit_Configuration RDS :
➤ Paramètres
Voici les paramètres de création du modèle cloudformation :
--s3-bucket:[Facultatif]Le nom du compartiment S3 du modèle CloudFormation duConditions préalables.vpcID:[Requis]L’identifiant du VPC duConditions préalables. Les lambdas de la machine à états Trapheus seront créés dans ce VPC.Subnets:[Requis]Une liste d’identifiants de sous-réseau privés (spécifiques à la région) séparés par des virgulesConditions préalablesVPC.SenderEmail:[Requis]L’email d’envoi SES configuré dans leConditions préalablesRecipientEmail:[Requis]Liste séparée par des virgules des adresses e-mail des destinataires configurées dansConditions préalables.UseVPCAndSubnets:[Facultatif]S’il faut utiliser le vpc et les sous-réseaux pour créer un groupe de sécurité et lier le groupe de sécurité et le vpc aux lambdas. Lorsque UseVPCAndSubnets est laissé de côté (par défaut) ou défini sur « true », les lambdas sont connectés à un VPC dans votre compte et, par défaut, la fonction ne peut pas accéder au RDS (ou à d’autres services) si le VPC ne fournit pas d’accès (soit par acheminer le trafic sortant vers unPasserelle NATdans un sous-réseau public, ou avoir unPoint de terminaison d’un VPC, qui entraînent tous deux des coûts ou nécessitent une configuration supplémentaire). S’il est défini sur « false », lelambdas s’exécutera dans un VPC par défaut appartenant à Lambda qui a accès à RDS (et à d’autres services AWS).SlackWebhookUrls:[Facultatif]Liste de webhooks Slack séparés par des virgules pour les alertes d’échec.
➤ Instructions
Installation
Pour configurer le Trapheus dans votre compte AWS, suivez les étapes ci-dessous :
- Cloner le dépôt Trapheus Git
- Configuration des informations d’identification AWS. Trapheus utilise boto3 comme bibliothèque client pour communiquer avec Amazon Web Services. Ne hésitez pas àutiliser n’importe quelle variable d’environnementque boto3 prend en charge pour fournir des informations d’authentification.
- Courir
pip install -r requirements.txtpour installer le graphe de dépendances - Courir
python install.py

Vous êtes toujours confronté à un problème ? Vérifier laProblèmessection ou ouvrir un nouveau numéro
Ce qui précède configurera un CFT dans votre compte AWS avec le nom fourni lors de l’installation.
A NOTER: Le CFT crée les ressources suivantes :
- DBRestoreStateMachineMachine à états de fonction étape
- Plusieurs lambdas pour exécuter différentes étapes dans la machine à états
- LambdaExecutionRole : utilisé dans tous les lambdas pour effectuer plusieurs tâches sur RDS
- StatesExecutionRole : rôle IAM avec des autorisations pour exécuter la machine d’état et appeler des lambdas
- Compartiment S3 : rds-snapshots-<your_account_id> où les instantanés seront exportés
- Clé KMS : est requise pour démarrer la tâche d’exportation de l’instantané vers s3
- DBRestoreStateMachineEventRule : une règle Cloudwatch à l’état désactivé, qui peut être utilisée comme ci-dessusinstructionsbasé sur les besoins de l’utilisateur
- CWEventStatesExecutionRole : rôle IAM utilisé par la règle DBRestoreStateMachineEventRule CloudWatch, pour permettre l’exécution de la machine d’état depuis CloudWatch
Pour configurer l’exécution de la fonction étape par étape via une exécution planifiée à l’aide de la règle CloudWatch, suivez les étapes ci-dessous :
- Accédez à la section DBRestoreStateMachineEventRule dans le template.yaml du dépôt Trapheus.
-
Nous l’avons défini comme règle cron planifiée pour qu’elle s’exécute tous les VENDREDI à 8h00 UTC. Vous pouvez le modifier selon votre fréquence de programmation préférée en mettant à jour leExpressionHorairela valeur de la propriété en conséquence. Exemples:
- Pour l’exécuter tous les 7 jours,
ScheduleExpression: "rate(7 days)" - Pour l’exécuter tous les VENDREDI à 8h00 UTC,
ScheduleExpression: "cron(0 8 ? * FRI *)"
Cliquez suricipour tous les détails sur la façon de définir ScheduleExpression.
- Pour l’exécuter tous les 7 jours,
-
Exemples de cibles données dans le fichier modèle sousCiblesla propriété pour votre référence doit être mise à jour :
un. ChangementSaisirpropriété en fonction des valeurs de votre propriété d’entrée, donnez en conséquence un meilleur identifiant pour votre cible en mettant à jour leIdentifiantpropriété.
b. En fonction du nombre de cibles pour lesquelles vous souhaitez définir la planification, ajoutez ou supprimez les cibles.
- Changer laÉtatvaleur de la propriété àACTIVÉ
- Enfin, emballez et redéployez la pile en suivant les étapes 2 et 3 dansConfiguration de l’escalier
➤ Exécution
Pour exécuter la fonction étape, suivez les étapes ci-dessous :
- Accédez à la définition de la machine d’état à partir du_Ressources_dans la pile cloudformation.
- Cliquer sur_Démarrer l’exécution_.
-
Sous_Saisir_, fournissez le json suivant comme paramètre :
{ “identifier”: “
", "task": " ", "isCluster": true or false }
un.identifier: (Obligatoire - Chaîne) L’instance RDS ou l’identifiant de cluster qui doit être restauré. Tout type d’instance RDS ou de clusters Amazon Aurora est pris en charge.
b.task: (Obligatoire - Chaîne) Les options valides sontcreate_snapshotoudb_restore or create_snapshot_only.
c.isCluster: (Obligatoire - Booléen) Définir surtruesi l’identifiant fourni est celui d’un cluster, sinon défini surfalse
La machine à états peut effectuer l’une des tâches suivantes :
- si
taskest réglé surcreate_snapshot, la machine d’état crée/met à jour un instantané pour l’instance ou le cluster RDS donné à l’aide de l’identifiant de l’instantané :identifier-instantané puis exécute le pipeline - si
taskest réglé surdb_restore, la machine d’état effectue une restauration sur l’instance RDS donnée, sans mettre à jour un instantané, en supposant qu’il existe un instantané avec un identifiant :identifier-instantané - si
taskest réglé surcreate_snapshot_only, la machine d’état crée/met à jour un instantané pour l’instance ou le cluster RDS donné à l’aide de l’identifiant de l’instantané :identifier-instantané et il n’exécuterait pas le pipeline
Considérations relatives aux coûts
Une fois le développement ou l’utilisation de l’outil terminé :
- si vous n’avez pas besoin de l’instance RDS lorsque vous ne codez pas ou n’utilisez pas l’outil (par exemple, s’il s’agit d’un RDS de test), envisagez d’arrêter ou de supprimer la base de données. Vous pouvez toujours le recréer quand vous en avez besoin.
- si vous n’avez pas besoin des anciens modèles Cloud Formation, il est recommandé de vider le compartiment CFN S3.
Démolir
Pour démonter votre application et supprimer toutes les ressources associées à la machine d’état Trapheus DB Restore, procédez comme suit :
- Connectez-vous auConsole Amazon CloudFormationet trouvez la pile que vous avez créée.
- Supprimez la pile. Notez que la suppression de la pile échouera si le compartiment rds-snapshots-<YOUR_ACCOUNT_NO> s3 n’est pas vide, supprimez donc d’abord les exportations d’instantanés dans le compartiment.
- Supprimez les ressources AWS duConditions préalables. La suppression de SES, du compartiment CFN S3 (videz-le si vous ne le supprimez pas) et de VPC est facultative car vous ne verrez pas les frais, mais vous pourrez les réutiliser plus tard pour un démarrage rapide.
➤ Comment ça marche
Pipeline complet
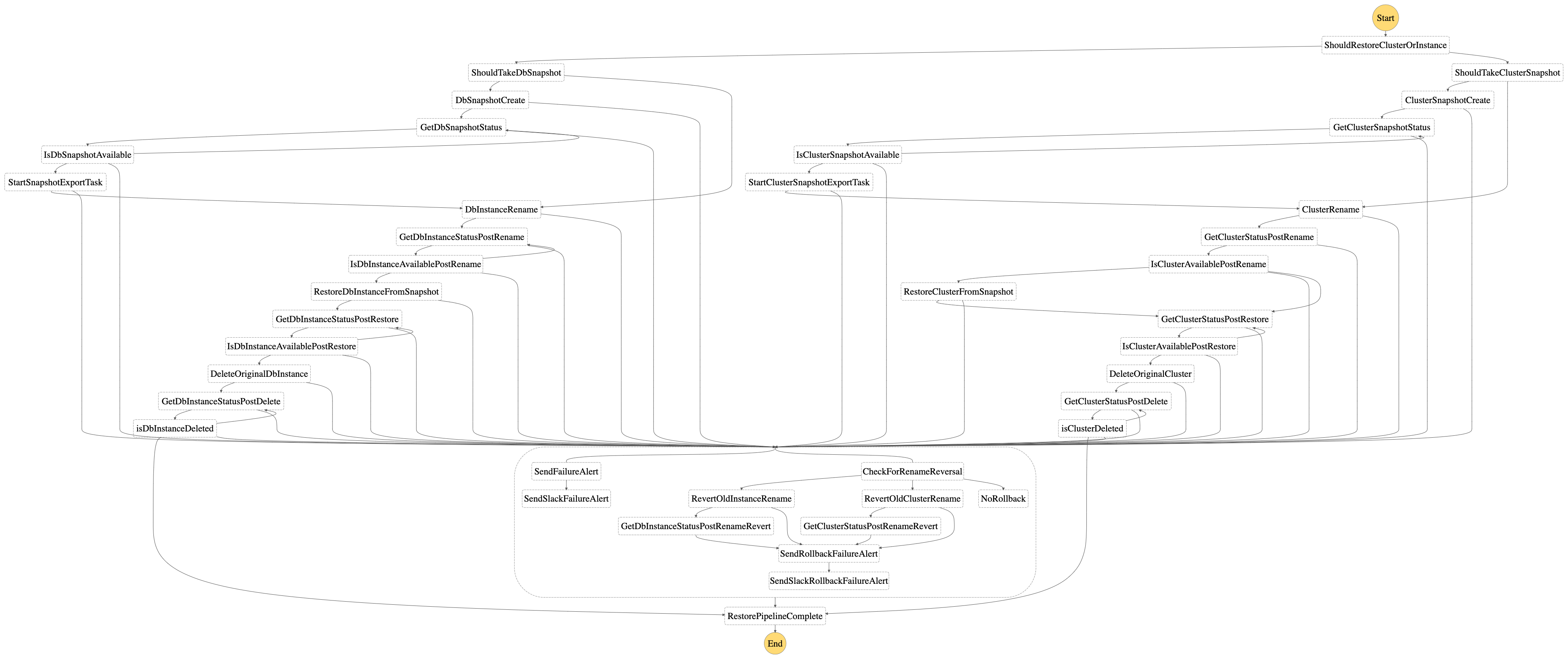
Modélisées comme une machine à états, différentes étapes du flux telles que la création/mise à jour d’instantanés, le renommage de l’instance, la restauration et la suppression, l’état d’achèvement/d’échec de chaque opération, l’alerte par e-mail d’échec, etc. sont exécutées à l’aide de lambdas individuels pour les instances de base de données et les clusters de base de données. respectivement. Pour suivre l’achèvement/l’échec de chaque opération, les serveurs RDS sont utilisés avec des délais et un nombre maximal de tentatives configurés en fonction du délai d’expiration lambda. Pour les scénarios de disponibilité et de suppression de cluster de bases de données, des serveurs personnalisés ont été définis. Les couches Lambda sont utilisées dans tous les lambdas pour les méthodes utilitaires courantes et la gestion personnalisée des exceptions.
Sur la base des commentaires fournis auDBRestoreStateMachinefonction step, les étapes/branches suivantes sont exécutées :
-
En utilisant le
isClustervaleur, un branchement a lieu dans la machine à états pour exécuter le pipeline pour un cluster de base de données ou pour une instance de base de données. -
Si
taskest réglé surcreate_snapshot, lecréation/mise à jour d’instantanésle processus a lieu respectivement pour un cluster ou une instance. Crée un instantané à l’aide de l’identifiant unique :identifier-instantané, s’il n’existe pas. Si un instantané existe déjà avec l’identifiant susmentionné, il est supprimé et un nouvel instantané est créé. -
Si
taskest réglé surdb_restore, le processus de restauration de la base de données démarre, sans création/mise à jour d’instantané -
Si
taskest réglé surcreate_snapshot_only, lecréation/mise à jour d’instantanésle processus n’a lieu que pour un cluster ou une instance respectivement. Crée un instantané à l’aide de l’identifiant unique :identifier-instantané, s’il n’existe pas. Si un instantané existe déjà avec l’identifiant susmentionné, il est supprimé et un nouvel instantané est créé. -
Dans le cadre du processus de restauration de la base de données, la première étape estRenommerde l’instance de base de données ou du cluster de base de données fourni et de ses instances correspondantes à un nom temporaire. Attendez la réussite de l’étape de renommage pour pouvoir utiliser le nom unique fourni.
identifierdans l’étape de restauration. -
Une fois l’étape de renommage terminée, l’étape suivante consiste àRestaurerl’instance de base de données ou le cluster de base de données à l’aide du
identifierparamètre et l’identifiant de l’instantané comme_identifier_-instantané -
Une fois la restauration terminée et l’instance de base de données ou le cluster de base de données disponible, la dernière étape consiste àSupprimerl’instance ou le cluster initialement renommé (ainsi que ses instances) qui a été conservé à des fins de gestion des échecs. Exécuté à l’aide de lambdas créés à des fins de suppression, une fois la suppression réussie, le pipeline est terminé.
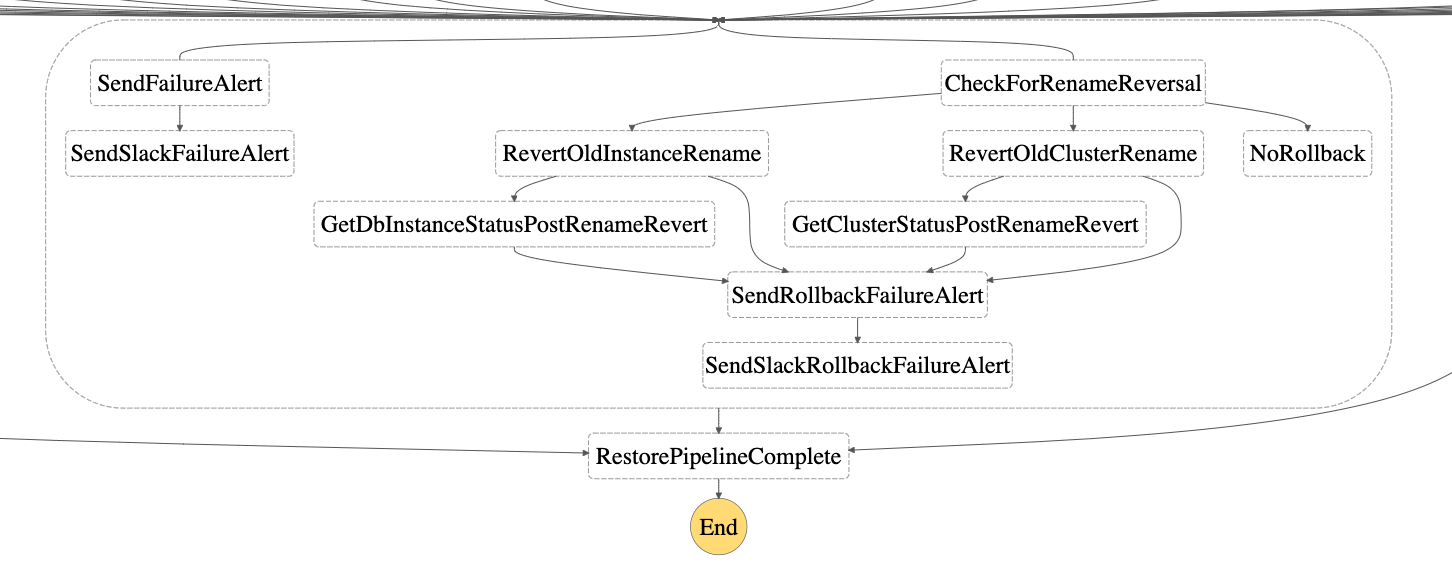
-
À chaque étape, les tentatives avec alertes d’interruption et d’échec sont traitées à chaque étape de la machine à états. En cas de panne, une alerte par e-mail SES est envoyée comme configuré lors de la configuration. En option, si
SlackWebhookUrlsa été fourni dans leinstallation, les notifications d’échec seront également envoyées aux canaux appropriés. -
Si l’étape de restauration échoue, dans le cadre de la gestion des échecs, leÉtape 4Le changement de nom de l’instance/du cluster est inversé pour garantir que l’instance de base de données ou le cluster de base de données d’origine est disponible pour utilisation.
Article du blog Amazon:https://aws.amazon.com/blogs/opensource/what-is-trapheus/
➤ Contribuer à Trapheus
Structure du code de référence
├── CONTRIBUTING.md <-- How to contribute to Trapheus
├── LICENSE.md <-- The MIT license.
├── README.md <-- The Readme file.
├── events
│ └── event.json <-- JSON event file to be used for local SAM testing
├── screenshots <-- Folder for screenshots of teh state machine.
│ ├── Trapheus-logo.png
│ ├── cluster_restore.png
│ ├── cluster_snapshot_branch.png
│ ├── failure_handling.png
│ ├── instance_restore.png
│ ├── instance_snapshot_branch.png
│ ├── isCluster_branching.png
│ └── restore_state_machine.png
├── src
│ ├── checkstatus
│ │ ├── DBClusterStatusWaiter.py <-- Python Waiter(https://boto3.amazonaws.com/v1/documentation/api/latest/guide/clients.html#waiters) for checking the status of the cluster
│ │ ├── get_dbcluster_status_function.py <-- Python Lambda code for polling the status of a clusterised database
│ │ ├── get_dbstatus_function.py <-- Python Lambda code for polling the status of a non clusterised RDS instance
│ │ └── waiter_acceptor_config.py <-- Config module for the waiters
│ ├── common <-- Common modules across the state machine deployed as a AWS Lambda layer.
│ │ ├── common.zip
│ │ └── python
│ │ ├── constants.py <-- Common constants used across the state machine.
│ │ ├── custom_exceptions.py <-- Custom exceptions defined for the entire state machine.
│ │ └── utility.py <-- Utility module.
│ ├── delete
│ │ ├── cluster_delete_function.py <-- Python Lambda code for deleting a clusterised database.
│ │ └── delete_function.py <-- Python Lambda code for deleting a non clusterised RDS instance.
│ ├── emailalert
│ │ └── email_function.py <-- Python Lambda code for sending out failure emails.
│ ├── rename
│ │ ├── cluster_rename_function.py <-- Python Lambda code for renaming a clusterised database.
│ │ └── rename_function.py <-- Python Lambda code for renaming a non-clusterised RDS instance.
│ ├── restore
│ │ ├── cluster_restore_function.py <-- Python Lambda code for retoring a clusterised database.
│ │ └── restore_function.py <-- Python Lambda code for restoring a non-clusterised RDS instance
│ ├── slackNotification
│ │ └── slack_notification.py <-- Python Lambda code for sending out a failure alert to configured webhook(s) on Slack.
│ └── snapshot
│ ├── cluster_snapshot_function.py <-- Python Lambda code for creating a snapshot of a clusterised database.
│ └── snapshot_function.py <-- Python Lambda code for creating a snapshot of a non-clusterised RDS instance.
├── template.yaml <-- SAM template definition for the entire state machine.
└── tests <-- Test folder.
└── unit
├── mock_constants.py
├── mock_custom_exceptions.py
├── mock_import.py
├── mock_utility.py
├── test_cluster_delete_function.py
├── test_cluster_rename_function.py
├── test_cluster_restore_function.py
├── test_cluster_snapshot_function.py
├── test_delete_function.py
├── test_email_function.py
├── test_get_dbcluster_status_function.py
├── test_get_dbstatus_function.py
├── test_rename_function.py
├── test_restore_function.py
├── test_slack_notification.py
└── test_snapshot_function.py
Préparez votre environnement. Installez les outils selon vos besoins.
- Git-Bashutilisé pour exécuter Git à partir de la ligne de commande.
- Bureau GithubOutil de bureau Git pour gérer les demandes d’extraction, les branches et les dépôts.
- Code de Visual StudioÉditeur visuel complet. Des extensions pour GitHub peuvent être ajoutées.
- Ou un éditeur de votre choix.
-
Dépôt Fork Trapheus
- Créez une branche fonctionnelle.
git branch trapheus-change1 - Confirmez la branche active pour les modifications.
git checkout trapheus-change1Vous pouvez combiner les deux commandes en tapant
git checkout -b trapheus-change1. -
Apportez des modifications localement à l’aide d’un éditeur et ajoutez des tests unitaires si nécessaire.
- Exécutez la suite de tests dans le référentiel pour vous assurer que les flux existants ne sont pas interrompus.
cd Trapheus python -m pytest tests/ -v #to execute the complete test suite python -m pytest tests/unit/test_get_dbstatus_function.py -v #to execute any individual test - Mettez en scène les fichiers édités.
git add contentfile.mdOu utiliser
git add .pour plusieurs fichiers. - Validez les modifications à partir de la préparation.
git commit -m "trapheus-change1" - Appliquer de nouvelles modifications à GitHub
git push --set-upstream origin trapheus-change1 - Vérifier le statut de la succursale
git statusRevoir
Outputpour confirmer le statut de validation. - Git pousser
git push --set-upstream origin trapheus-change1 - Le
Outputfournira un lien pour créer votre Pull Request.
➤ Contributeurs