Trapheus

Restore RDS instances in AWS without worrying about client downtime or configuration retention.
Trapheus can restore individual RDS instance or a RDS cluster.
Modelled as a state machine, with the help of AWS step functions, Trapheus restores the RDS instance in a much faster way than the usual SQL dump preserving the same instance endpoint and confgurations as before.

![]()


- 重要的:此应用程序使用各种 AWS 服务,并且在使用免费套餐后会产生与这些服务相关的费用 - 请参阅AWS 定价页面了解详情。
📖 Table of Contents
[](#table-of-contents) ## ➤ 目录 - - [➤ 先决条件](#-pre-requisites) - - [➤ 参数](#-parameters) - - [➤ 使用说明](#-instructions) - - [➤ 执行](#-execution) - - [➤ 工作原理](#-how-it-works) - - [➤ 为 Trapheus 做出贡献](#-contributing-to-trapheus) - - [➤ 贡献者](#-contributors) - - [➤ 表达你的支持](#-show-your-support)

➤ 先决条件
该应用程序在安装前需要以下 AWS 资源:
-
python3.11安装在本地计算机上如下这. - 配置AWSSES
- 配置 SES 发件人和收件人电子邮件(SES控制台->电子邮件地址)。
- SES 电子邮件警报配置为通知用户状态机中的任何故障。需要sender email参数来配置发送警报的电子邮件ID。需要接收者电子邮件参数来设置警报发送到的电子邮件 ID。
- 配置 SES 发件人和收件人电子邮件(SES控制台->电子邮件地址)。
- 创建系统将存储云形成模板的 S3 存储桶:
- 建议名称:trapheus-cfn-s3-[帐户ID-]-[地区]。建议该名称包含您的:
- account-id,因为存储桶名称需要是全局的(防止其他人具有相同的名称)
- 区域,以便在多个区域有 trapeus-s3 存储桶时轻松跟踪
- 建议名称:trapheus-cfn-s3-[帐户ID-]-[地区]。建议该名称包含您的:
- VPC(特定于区域)。相同的 VPC/区域应用于 Trapheus 中使用的 RDS 实例和 Trapheus 的 lambda。
- 区域选择考虑。支持的地区:
- 最小 VPC 设置示例:
- 专有网络控制台:
- 名称: Trapheus-VPC-[地区](指定[地区]创建 VPC 的位置 - 当您在多个区域拥有 Trapheus-VPC 时可以轻松跟踪)
- IPv4 CIDR 块: 10.0.0.0/16
- VPC控制台->子网页面并创建两个私有子网:
- 子网1:
- VPC: Trapheus-VPC-[地区]
- 可用区域:选择一个
- IPv4 CIDR 块:10.0.0.0/19
- 子网2:
- VPC: Trapheus-VPC-[地区]
- 可用区:选择与 Subnet1 AZ 不同的可用区。
- IPv4 CIDR 块:10.0.32.0/19
- 子网1:
- 您创建了一个只有两个私有子网的 VPC。如果您要创建非私有子网,请检查私有子网、公有子网、具有专用自定义网络 ACL 的私有子网和备用容量之间的比率.
- 专有网络控制台:
- 您想要恢复的 RDS 数据库的一个或多个实例。
- 最小示例_自由的_RDS 设置:
- 引擎选项:MySQL
- 模板:免费套餐
- 设置:输入密码
- 连接性:VPC:Trapeus-VPC-[地区]
- 最小示例_自由的_RDS 设置:
➤ 参数
创建cloudformation模板的参数如下:
--s3-bucket:[选修的]CloudFormation 模板 S3 存储桶的名称先决条件.vpcID:[必需的]来自 VPC 的 id先决条件。来自 Trapheus 状态机的 lambda 将在此 VPC 中创建。Subnets:[必需的]私有子网 ID(特定于区域)的逗号分隔列表先决条件专有网络。SenderEmail:[必需的]中配置的SES发送电子邮件先决条件RecipientEmail:[必需的]在中配置的收件人电子邮件地址的逗号分隔列表先决条件.UseVPCAndSubnets:[选修的]是否使用 vpc 和子网创建安全组并将安全组和 vpc 链接到 lambda。当 UseVPCAndSubnets 省略(默认)或设置为“true”时,lambda 将连接到您账户中的 VPC,并且默认情况下,如果 VPC 不提供访问权限(通过以下方式),则该函数无法访问 RDS(或其他服务):将出站流量路由到NAT网关在公共子网中,或者有一个VPC端点,两者都会产生成本或需要更多设置)。如果设置为“假”,则lambdas 将在默认的 Lambda 拥有的 VPC 中运行,该 VPC 可以访问 RDS(和其他 AWS 服务).SlackWebhookUrls:[选修的]用于故障警报的 Slack Webhook 的逗号分隔列表。
➤ 使用说明
设置
要在您的 AWS 账户中设置 Trapheus,请按照以下步骤操作:
- 克隆 Trapheus Git 存储库
- AWS 凭证配置。 Trapheus 使用 boto3 作为客户端库与 Amazon Web Services 进行通信。随意地使用任何环境变量boto3 支持提供身份验证凭据。
- 跑步
pip install -r requirements.txt安装依赖图 - 跑步
python install.py

仍然面临问题吗?检查问题部分或打开一个新问题
上述操作将使用安装期间提供的名称在您的 AWS 账户中设置一个 CFT。
需要注意的是: CFT 创建以下资源:
- 数据库恢复状态机阶跃函数状态机
- 多个 lambda 表达式用于执行状态机中的各个步骤
- LambdaExecutionRole:在所有 lambda 中使用,以跨 RDS 执行多个任务
- StatesExecutionRole:具有执行状态机和调用 lambda 权限的 IAM 角色
- S3 存储桶:rds-snapshots-<your_account_id> 快照将导出到的位置
- KMS 密钥:需要启动快照到 s3 的导出任务
- DBRestoreStateMachineEventRule:处于禁用状态的 Cloudwatch 规则,可以按照上面的方式使用指示根据用户要求
- CWEventStatesExecutionRole:DBRestoreStateMachineEventRule CloudWatch 规则使用的 IAM 角色,以允许从 CloudWatch 执行状态机
要使用 CloudWatch 规则通过计划运行设置步骤函数执行,请按照以下步骤操作:
- 转到 Trapheus 存储库的 template.yaml 中的 DBRestoreStateMachineEventRule 部分。
-
我们已将其设置为计划的 cron 规则,在每个星期五上午 8:00 UTC 运行。您可以通过更新将其更改为您首选的计划频率时间表表达式相应的财产价值。例子:
- 每 7 天运行一次,
ScheduleExpression: "rate(7 days)" - 要在世界标准时间 (UTC) 每周五上午 8:00 运行它,
ScheduleExpression: "cron(0 8 ? * FRI *)"
点击这里有关如何设置 ScheduleExpression 的所有详细信息。
- 每 7 天运行一次,
-
下的模板文件中给出的示例目标目标供您参考的属性必须更新:
A。改变输入根据您的输入属性值,相应地通过更新为您的目标提供更好的 IDID财产。
b.根据您要为其设置计划的目标数量,添加或删除目标。
- 改变状态财产价值为启用
- 最后,按照中的步骤 2 和 3 打包并重新部署堆栈楼梯设置
➤ 执行
要执行步骤功能,请按照以下步骤操作:
- 从以下位置导航到状态机定义_资源_cloudformation 堆栈中的选项卡。
- 点击_开始执行_.
-
在下面_输入_,提供以下 json 作为参数:
{ “identifier”: “
", "task": " ", "isCluster": true or false }
A。identifier:(必需 - 字符串)必须恢复的 RDS 实例或集群标识符。这里支持任何类型的 RDS 实例或 Amazon aurora 集群。
b.task:(必需 - 字符串)有效选项是create_snapshot或者db_restore或者create_snapshot_only.
C。isCluster:(必需 - 布尔值)设置为true如果提供的标识符是集群的,则设置为false
状态机可以执行以下任务之一:
- 如果
task被设定为create_snapshot,状态机使用快照标识符为给定 RDS 实例或集群创建/更新快照:标识符-snapshot 然后执行管道 - 如果
task被设定为db_restore,状态机在给定的 RDS 实例上执行恢复,而不更新快照,假设存在带有标识符的现有快照:标识符-快照 - 如果
task被设定为create_snapshot_only,状态机使用快照标识符为给定 RDS 实例或集群创建/更新快照:标识符-snapshot,它不会执行管道
成本考虑
完成开发或使用该工具后:
- 如果您在不编码或使用该工具时不需要 RDS 实例(例如,如果它是测试 RDS),请考虑停止或删除数据库。您随时可以在需要时重新创建它。
- 如果您不需要过去的Cloud Formation模板,建议您清空CFN S3存储桶。
拆除
要拆除您的应用程序并删除与 Trapheus DB Restore 状态机关联的所有资源,请执行以下步骤:
- 登录Amazon CloudFormation 控制台并找到您创建的堆栈。
- 删除堆栈。请注意,如果 rds-snapshots-<YOUR_ACCOUNT_NO> s3 存储桶不为空,堆栈删除将会失败,因此请先删除存储桶中快照的导出。
- 从以下位置删除 AWS 资源先决条件。删除 SES、CFN S3 存储桶(如果不删除则将其清空)和 VPC 是可选的,因为您不会看到费用,但可以稍后重新使用它们以快速启动。
➤ 工作原理
完整的管道
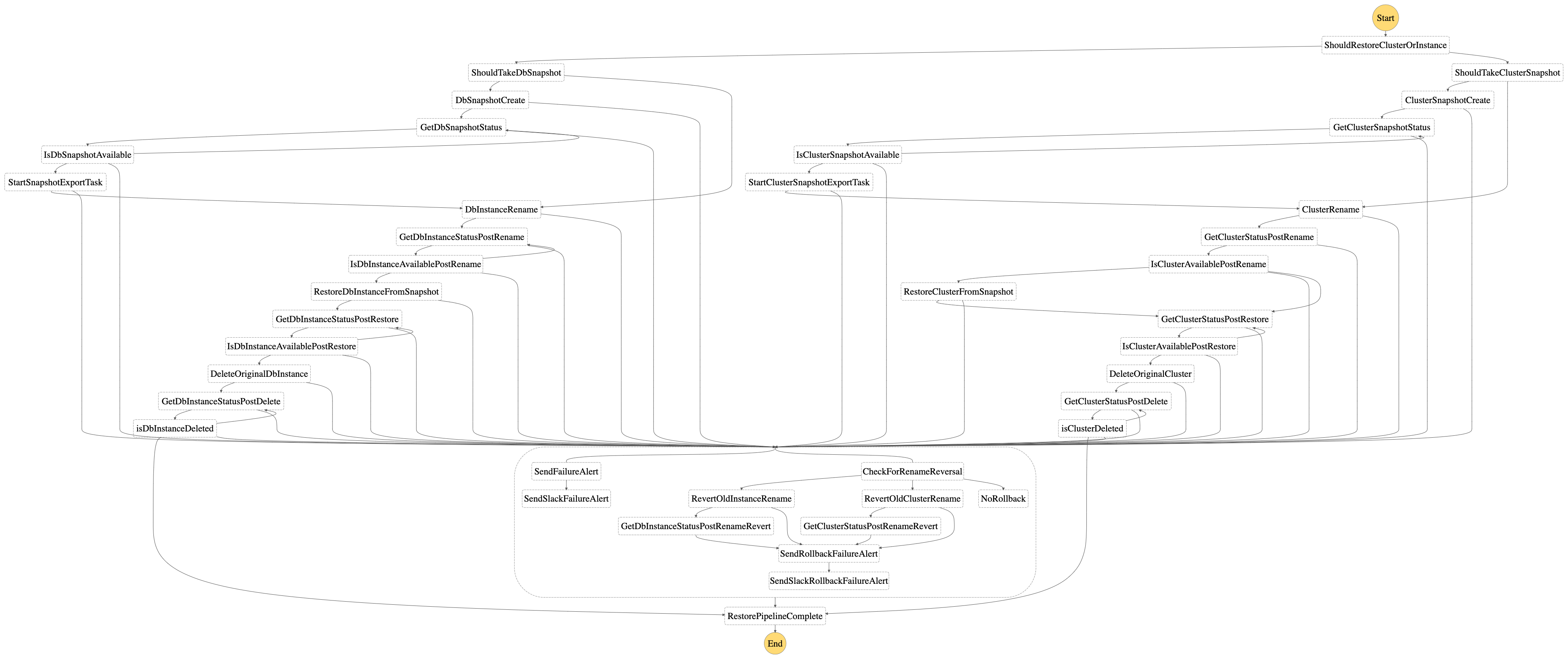
建模为状态机,流程中的不同步骤(例如快照创建/更新、实例重命名、恢复和删除、每个操作的完成/失败状态、失败电子邮件警报等)是使用数据库实例和数据库集群的单独 lambda 执行的分别。 为了跟踪每个操作的完成/失败,使用 RDS 等待程序,并根据 lambda 超时配置延迟和最大重试尝试次数。针对数据库集群可用和删除的场景,定义了自定义服务员。 Lambda 层用于所有 lambda 中的通用实用方法和自定义异常处理。
根据提供给的输入数据库恢复状态机步骤函数,执行以下步骤/分支:
-
使用
isCluster值时,状态机中会发生分支以执行数据库集群或数据库实例的管道。 -
如果
task被设定为create_snapshot, 这快照创建/更新进程分别针对集群或实例进行。 使用唯一标识符创建快照:标识符-快照,如果不存在。如果具有上述标识符的快照已存在,则将其删除并创建新快照。 -
如果
task被设定为db_restore,数据库恢复过程开始,没有快照创建/更新 -
如果
task被设定为create_snapshot_only, 这快照创建/更新该过程仅分别针对集群或实例进行。 使用唯一标识符创建快照:标识符-快照,如果不存在。如果具有上述标识符的快照已存在,则将其删除并创建新快照。 -
作为数据库恢复过程的一部分,第一步是改名将提供的数据库实例或数据库集群及其对应的实例命名为临时名称。 等待重命名步骤成功完成才能使用提供的唯一名称
identifier在恢复步骤中。 -
重命名步骤完成后,下一步是恢复数据库实例或数据库集群使用
identifier参数和快照 ID 为_标识符_-快照 -
恢复完成并且数据库实例或数据库集群可用后,最后一步是删除最初重命名的实例或集群(及其实例),保留用于故障处理目的。 使用为删除目的而创建的 lambda 执行,一旦删除成功,管道就完成了。
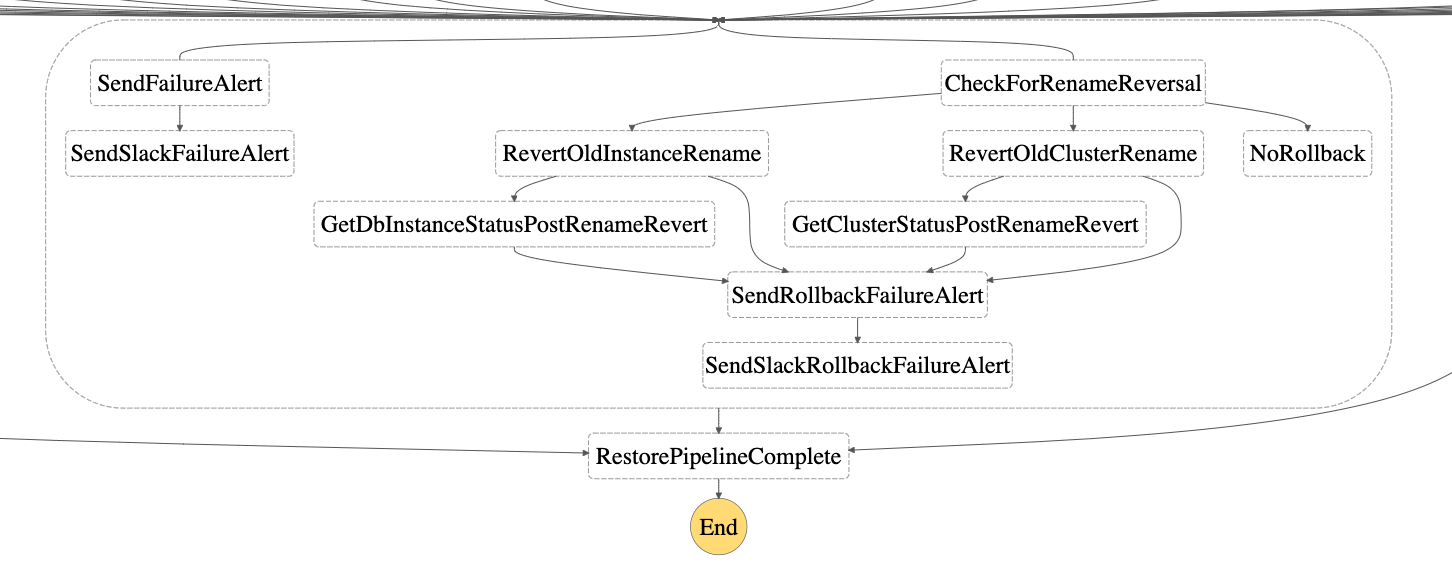
-
在任何步骤中,状态机的每个步骤都会处理带有退避和失败警报的重试。如果发生故障,则会按照设置期间的配置发送 SES 电子邮件警报。可选地,如果
SlackWebhookUrls中提供了设置,失败通知也会发送到相应的渠道。 -
如果恢复步骤失败,作为故障处理的一部分,步骤4恢复实例/集群重命名以确保原始数据库实例或数据库集群可供使用。
亚马逊博客文章:HTTPS://AWS.Amazon.com/blogs/open source/what-is-trap和US/
➤ 为 Trapheus 做出贡献
参考代码结构
├── CONTRIBUTING.md <-- How to contribute to Trapheus
├── LICENSE.md <-- The MIT license.
├── README.md <-- The Readme file.
├── events
│ └── event.json <-- JSON event file to be used for local SAM testing
├── screenshots <-- Folder for screenshots of teh state machine.
│ ├── Trapheus-logo.png
│ ├── cluster_restore.png
│ ├── cluster_snapshot_branch.png
│ ├── failure_handling.png
│ ├── instance_restore.png
│ ├── instance_snapshot_branch.png
│ ├── isCluster_branching.png
│ └── restore_state_machine.png
├── src
│ ├── checkstatus
│ │ ├── DBClusterStatusWaiter.py <-- Python Waiter(https://boto3.amazonaws.com/v1/documentation/api/latest/guide/clients.html#waiters) for checking the status of the cluster
│ │ ├── get_dbcluster_status_function.py <-- Python Lambda code for polling the status of a clusterised database
│ │ ├── get_dbstatus_function.py <-- Python Lambda code for polling the status of a non clusterised RDS instance
│ │ └── waiter_acceptor_config.py <-- Config module for the waiters
│ ├── common <-- Common modules across the state machine deployed as a AWS Lambda layer.
│ │ ├── common.zip
│ │ └── python
│ │ ├── constants.py <-- Common constants used across the state machine.
│ │ ├── custom_exceptions.py <-- Custom exceptions defined for the entire state machine.
│ │ └── utility.py <-- Utility module.
│ ├── delete
│ │ ├── cluster_delete_function.py <-- Python Lambda code for deleting a clusterised database.
│ │ └── delete_function.py <-- Python Lambda code for deleting a non clusterised RDS instance.
│ ├── emailalert
│ │ └── email_function.py <-- Python Lambda code for sending out failure emails.
│ ├── rename
│ │ ├── cluster_rename_function.py <-- Python Lambda code for renaming a clusterised database.
│ │ └── rename_function.py <-- Python Lambda code for renaming a non-clusterised RDS instance.
│ ├── restore
│ │ ├── cluster_restore_function.py <-- Python Lambda code for retoring a clusterised database.
│ │ └── restore_function.py <-- Python Lambda code for restoring a non-clusterised RDS instance
│ ├── slackNotification
│ │ └── slack_notification.py <-- Python Lambda code for sending out a failure alert to configured webhook(s) on Slack.
│ └── snapshot
│ ├── cluster_snapshot_function.py <-- Python Lambda code for creating a snapshot of a clusterised database.
│ └── snapshot_function.py <-- Python Lambda code for creating a snapshot of a non-clusterised RDS instance.
├── template.yaml <-- SAM template definition for the entire state machine.
└── tests <-- Test folder.
└── unit
├── mock_constants.py
├── mock_custom_exceptions.py
├── mock_import.py
├── mock_utility.py
├── test_cluster_delete_function.py
├── test_cluster_rename_function.py
├── test_cluster_restore_function.py
├── test_cluster_snapshot_function.py
├── test_delete_function.py
├── test_email_function.py
├── test_get_dbcluster_status_function.py
├── test_get_dbstatus_function.py
├── test_rename_function.py
├── test_restore_function.py
├── test_slack_notification.py
└── test_snapshot_function.py
准备您的环境。根据需要安装工具。
- git 重击用于从命令行运行 Git。
- Github 桌面用于管理拉取请求、分支和存储库的 Git 桌面工具。
- 视觉工作室代码完整的可视化编辑器。可以添加 GitHub 的扩展。
- 或者您选择的编辑器。
-
Fork Trapheus 仓库
- 创建一个工作分支。
git branch trapheus-change1 - 确认工作分支进行更改。
git checkout trapheus-change1您可以通过键入来组合这两个命令
git checkout -b trapheus-change1. -
使用编辑器在本地进行更改并根据需要添加单元测试。
- 在存储库中运行测试套件以确保现有流程不会中断。
cd Trapheus python -m pytest tests/ -v #to execute the complete test suite python -m pytest tests/unit/test_get_dbstatus_function.py -v #to execute any individual test - 阶段编辑的文件。
git add contentfile.md或者使用
git add .对于多个文件。 - 提交暂存中的更改。
git commit -m "trapheus-change1" - 将新更改推送到 GitHub
git push --set-upstream origin trapheus-change1 - 验证分支的状态
git status审查
Output确认提交状态。 - git 推送
git push --set-upstream origin trapheus-change1 - 这
Output将提供一个链接来创建您的拉取请求。
➤ 贡献者