Scorer Selection Guide¶
Scorers determine how items are scored given user context. Choosing the right scorer depends on your data structure and modeling needs.
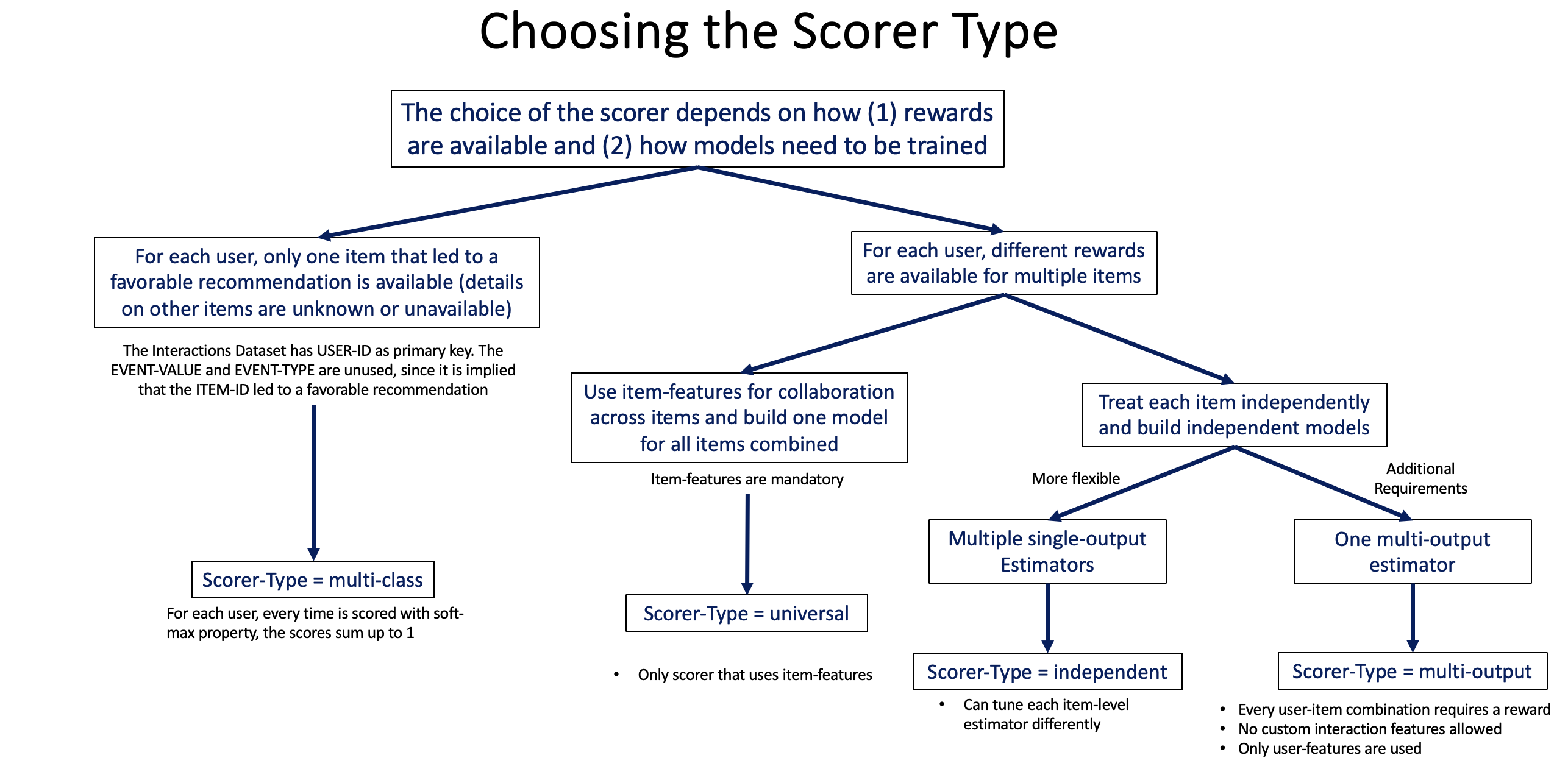
Quick Comparison¶
| Scorer | Models | Item Features | Use Case |
|---|---|---|---|
| Universal | 1 global model | ✅ Required | Best performance, needs item features. Also supports embedding estimators. |
| Independent | 1 model per item | ❌ Not used | Simple, no item features needed |
| Multiclass | 1 model | ❌ Not allowed | One positive item per user |
| Multioutput | 1 model | ❌ Not allowed | Multiple outcomes per user |
| Sequential | 1 sequential model | ❌ N/A | SASRec — scores from interaction sequences |
| Hierarchical | 1 sequential model | ❌ N/A | HRNN — scores from session-structured sequences |
1. UniversalScorer (Most Common)¶
How it works: Builds a single global model that learns patterns across all items using item features.
Dataset Requirements: - ✅ Interactions: Multiple rows per user allowed - ✅ Users: Required - ✅ Items: Required (item features are used) - 📊 Outcome: Binary (classification) or continuous (regression)
Pros: - Best performance (learns item similarities) - Handles new items if they have features - Efficient inference
Cons: - Requires item features - More complex setup
When to use: This is the default choice for most scenarios. Use when you have item metadata.
2. IndependentScorer¶
How it works: Builds separate models for each item. No sharing across items.
Dataset Requirements: - ✅ Interactions: Multiple rows per user allowed - ⚠️ Users: Optional - ❌ Items: Not used (no item features needed) - 📊 Outcome: Binary or continuous
Pros:
- Simple (no item features needed)
- Supports parallel inference: scorer.set_parallel_inference(parallel_inference_status=True, num_cores=4)
- Each item can have very different patterns
Cons: - No knowledge sharing across items - Cannot handle new items - Requires sufficient data per item
When to use: When you don't have item features, or each item needs a specialized model.
3. MulticlassScorer¶
How it works: Treats items as competing classes in a multiclass classification problem.
Dataset Requirements:
- ⚠️ Interactions: One row per user only (one positive item per user)
- ❌ Users: Not allowed
- ❌ Items: Not allowed
- 📊 Outcome: Not allowed (uses ITEM_ID as target)
Pros: - Simple data structure - Fast training and inference - Works well when users have clear single preferences
Cons: - Restrictive data format (one row per user) - No user or item features - Limited flexibility
When to use: Simple scenarios with one positive item per user and no additional features.
4. MultioutputScorer¶
How it works: Wide-format multi-target scorer — one ITEM_<name> column per target, all trained jointly. Operates in one of two modes depending on the estimator type:
- Classifier mode (with a
BaseClassifier, e.g.MultiOutputClassifierEstimator): every target must be binary numeric — values strictly in{0, 1}(or{0.0, 1.0}). Pre-encode non-numeric binary labels at the caller (e.g.df[col] = (df[col] == "yes").astype(float)). Returns per-class probabilities (uniform column namesITEM_<name>_0/ITEM_<name>_1), supports cross-target ranking metrics, per-label classification metrics, andrecommend(top_k)returning the top-K most-likely-positive labels per user. - Regressor mode (with a
BaseRegressor, e.g.MultiOutputRegressorEstimator): every target is continuous. Returns predicted values per target, supports per-target regression metrics (RMSE, MAE).
Multi-class targets (3+ classes per ITEM_<name>) are rejected at fit time. See Migration paths for multi-class targets below.
# Classifier mode — multi-label binary classification
from xgboost import XGBClassifier
from skrec.scorer.multioutput import MultioutputScorer
from skrec.estimator.classification.multioutput_classifier import (
MultiOutputClassifierEstimator,
)
estimator = MultiOutputClassifierEstimator(
base_estimator=XGBClassifier,
params={"n_estimators": 50, "max_depth": 4, "objective": "binary:logistic"},
)
scorer = MultioutputScorer(estimator)
# Regressor mode — multi-target regression
from xgboost import XGBRegressor
from skrec.scorer.multioutput import MultioutputScorer
from skrec.estimator.regression.multioutput_regressor import (
MultiOutputRegressorEstimator,
)
estimator = MultiOutputRegressorEstimator(
base_estimator=XGBRegressor,
params={"n_estimators": 50, "max_depth": 4, "objective": "reg:squarederror"},
)
scorer = MultioutputScorer(estimator)
Per-label vs joint estimators¶
MultioutputScorer is agnostic to how the N targets are modeled — only to the
output shape. Two model structures are supported:
- Per-label (N independent models).
MultiOutputClassifierEstimator/MultiOutputRegressorEstimatorwrapsklearn.MultiOutputClassifier/MultiOutputRegressor, which fit one separate booster per target. Simple and robust; no signal is shared across targets. - Joint (one model over all targets).
JointXGBMultiOutputClassifierEstimator(classifier mode) andJointXGBMultiOutputRegressorEstimator(regressor mode) train a single XGBoost booster on the 2-D target matrix. This matches a productionnum_target=Nrecipe and trains/serves one artifact.
from skrec.estimator.classification.joint_xgb_multioutput import (
JointXGBMultiOutputClassifierEstimator,
)
# one joint booster over all binary labels
scorer = MultioutputScorer(JointXGBMultiOutputClassifierEstimator({"n_estimators": 300}))
"Joint" ≠ cross-label learning by default. XGBoost's
multi_strategydecides whether targets share tree structure: -'one_output_per_tree'(default): separate trees per target inside one jointly-boosted model. GPU-capable. No cross-label learning — modeling-wise close to per-label. -'multi_output_tree'(vector leaf): splits chosen on the summed gradient across all targets, so targets share structure. Genuine cross-label learning, but CPU-only. Passparams={'multi_strategy': 'multi_output_tree'}to opt in; the estimator logs that it's active + CPU-only and warns if a GPUdevice/tree_methodwas also set.
- sklearn tree ensembles are joint for free.
RandomForestClassifier/ExtraTreesClassifier(and their regressors) natively accept a 2-D target matrix and grow multi-output trees that share structure across all targets by default (splits chosen on the averaged criterion across targets — genuine shared-representation learning). Their multilabelpredict_probaalready returns the list-of-blocks layout the scorer expects, so they work through the plainSklearnUniversalClassifierEstimator/SklearnUniversalRegressorEstimatorwith no dedicated estimator:
from sklearn.ensemble import RandomForestClassifier
from skrec.estimator.classification.sklearn_universal_classifier import (
SklearnUniversalClassifierEstimator,
)
scorer = MultioutputScorer(
SklearnUniversalClassifierEstimator(RandomForestClassifier, {"n_estimators": 200})
)
(Note: shared structure across targets is not the same as label conditioning
— none of these read one target's value to predict another. For real-time-label
conditioning use the MixedTypeMultiTargetScorer conditional estimators.)
Class weighting and fit-time parameters¶
All sklearn-API estimators (XGBoost / LightGBM / sklearn wrappers, single- and multi-target) accept a generic fit-time passthrough — no estimator-specific plumbing:
sample_weight: a row-weight strategy —'balanced'(compute_sample_weight('balanced', y)computed at fit time, the production firmographics recipe), a callablefn(y) -> weights, or an explicit array. Defaults to uniform.fit_params: a dict of static kwargs forwarded verbatim to the underlyingfit(feature_weights,base_margin, a custom objective,callbacks, …).
Tree-count pinning vs early stopping¶
To pin the number of trees (e.g. reproduce a production best_iteration), set
n_estimators in params and omit early_stopping_rounds. An XGBoost
eval_set is used only when validation data (X_valid) is passed to fit; with
no validation set, training runs the full pinned n_estimators.
Dataset Requirements:
- ⚠️ Interactions: One row per user only
- ❌ Users: Not allowed (pass user features as plain columns inside interactions)
- ❌ Items: Not allowed
- 📊 Targets: Multiple ITEM_<name> columns; binary in classifier mode, continuous in regressor mode
Example Data (classifier mode):
interactions_df = pd.DataFrame({
"USER_ID": ["user_1", "user_2"],
"age": [28, 41], # User feature, in-frame
"ITEM_label_workflow_automation": [1, 0],
"ITEM_label_dashboard": [0, 1],
"ITEM_label_custom_roles": [1, 0],
})
Example Data (regressor mode):
interactions_df = pd.DataFrame({
"USER_ID": ["user_1", "user_2"],
"age": [28, 41],
"ITEM_revenue": [125.50, 89.20],
"ITEM_minutes_engaged": [42.0, 18.5],
"ITEM_clicks": [12, 5],
})
Public introspection surface¶
Programmatic callers can inspect the scorer's mode and per-target metadata:
| Attribute / method | Type | Meaning |
|---|---|---|
scorer.is_classifier |
bool |
True for binary classifier mode (estimator is a BaseClassifier); False for regressor mode (BaseRegressor). Set at construction; immutable afterwards. |
scorer.item_names |
list[str] / np.ndarray[str] |
Every ITEM_<name> target seen at fit, in input order. Used to align logged_rewards columns with the trained catalogue. |
scorer.degenerate_targets |
Dict[str, float] |
Manifest of targets that fell back to a constant predictor under DegenerateTargetPolicy.CONSTANT — empty when RAISE is in effect (training would have aborted) or when no targets were degenerate. Maps target name → the only observed value (always 0.0 or 1.0 since the binary-only contract pins targets to {0, 1}). |
scorer.score_items_per_target(interactions=df) |
pd.DataFrame of shape (n_users, n_targets) |
Per-target relevance scores: positive-class probability per target in classifier mode, predicted value per target in regressor mode. Used internally by recommend() and evaluate() for ranking metrics; available as a public method for callers that want the per-target view directly. |
scorer.positive_proba_column_name(label) |
str |
The column name in score_items output carrying P(label = 1). Always returns f"{label}_1" since the binary-only contract pins the positive class to 1. Classifier mode only. |
Degenerate-target handling (on_degenerate_target)¶
A "degenerate" target is one whose training slice has only one unique value (no learning signal). The scorer's behaviour is configurable via the DegenerateTargetPolicy enum:
from skrec.scorer.multioutput import MultioutputScorer, DegenerateTargetPolicy
# Default: fail loudly at train() with the offending column names.
scorer = MultioutputScorer(estimator) # on_degenerate_target=DegenerateTargetPolicy.RAISE
# Opt-in: fit a constant predictor for degenerate columns; train the rest normally.
scorer = MultioutputScorer(
estimator,
on_degenerate_target=DegenerateTargetPolicy.CONSTANT,
)
Through the factory. Most callers reach MultioutputScorer via create_recommender_pipeline rather than direct construction. The same policy is reachable as a scorer_config block on the top-level config:
from skrec.orchestrator.factory import create_recommender_pipeline
config = {
"recommender_type": "ranking",
"scorer_type": "multioutput",
"estimator_config": {"ml_task": "classification"},
"scorer_config": {"on_degenerate_target": "constant"}, # or DegenerateTargetPolicy.CONSTANT
}
recommender = create_recommender_pipeline(config)
scorer_config accepts either the enum member or its string value. Passing keys a scorer doesn't accept raises ValueError upfront — the accepted keys per scorer are listed in capability_matrix()["scorer_config_keys"].
Under CONSTANT, recommender.scorer.degenerate_targets exposes the manifest of columns that fell back to constant prediction. Per-label classification metrics on degenerate targets emit nan (excluded from macro-mean), and ranking metrics drop them entirely (constant predictions would tie at the top of every per-user ranking and bias the metric).
recommend(top_k) also drops degenerate targets before ranking. A WARNING is logged once per recommender instance listing the excluded targets. If top_k exceeds the count of non-degenerate targets, the request is silently capped at the available count with a warning — callers that pre-allocate by top_k should account for this. If every target is degenerate (only reachable when an item_subset selects only degenerate columns), recommend() raises with a pointer at scorer.predict_classes() for the constant per-target labels.
Migration paths for multi-class targets¶
MultioutputScorer rejects multi-class targets (3+ classes per ITEM_<name>) at fit time. Pick the path that fits your shape:
- Wide format, any mix of multi-class + binary + regression + multilabel → use
MixedTypeMultiTargetScorerbelow. Multi-class targets are first-class viaTargetType.MULTICLASS; class labels are preserved end-to-end (no manual one-hot encoding, no label-encoder round-trips). This is the recommended path for new wide-format multi-target work. - Single multi-class target in long format → use
MulticlassScorer. Best when you have(USER_ID, ITEM_ID)rows andITEM_IDitself is the class label. - Legacy compatibility (stay on
MultioutputScorer) → one-hot encode each multi-class column into binary columns (e.g.ITEM_Xwith classes{A, B, C}becomesITEM_X_A,ITEM_X_B,ITEM_X_C, each binary). Only choose this if you have an existingMultioutputScorerpipeline you don't want to rewrite — option #1 handles the same data without the encoding step.
Pros: - Multi-label binary classification with cross-target ranking semantics - Multi-target regression with per-target diagnostics - One model for all targets (joint training, shared user features in-frame)
Cons: - Restrictive data format (one row per user; no separate users/items DataFrame) - Binary-only enforcement in classifier mode (multi-class targets must be reshaped) - All targets must be known at training time
When to use: A fixed set of binary outcomes per user (feature adoption, action labels) where you want both per-target diagnostics AND cross-target ranking ("top features this user is most likely to adopt"). For continuous outcomes, the regressor mode covers per-target prediction.
5. MixedTypeMultiTargetScorer¶
How it works: Wide-format scorer for heterogeneous per-target types in one model. Unlike MultioutputScorer (binary-only OR continuous-only — every target must share a mode), this scorer declares each target's type explicitly via target_specs and supports BINARY + REGRESSION + MULTICLASS + MULTILABEL groups in the same training frame.
from skrec.scorer.mixed_type_multi_target import (
MixedTypeMultiTargetScorer, TargetType, TargetGroupSpec,
)
from skrec.estimator.classification import JointMultiTargetMLPEstimator
target_specs = {
"ITEM_clicked": TargetType.BINARY,
"ITEM_revenue": TargetType.REGRESSION,
"ITEM_action": TargetType.MULTICLASS,
"engagement": TargetGroupSpec(
type=TargetType.MULTILABEL,
columns=["ITEM_email_open", "ITEM_app_open"],
),
}
estimator = JointMultiTargetMLPEstimator(target_specs=target_specs)
scorer = MixedTypeMultiTargetScorer(estimator=estimator, target_specs=target_specs)
target_specs syntax:
| Target type | Spec value | Column name |
|---|---|---|
| BINARY | TargetType.BINARY |
Key IS the column name (must be ITEM_-prefixed); values in {0, 1} |
| REGRESSION | TargetType.REGRESSION |
Key IS the column name; numeric values |
| MULTICLASS | TargetType.MULTICLASS |
Key IS the column name; any hashable labels (≥2 unique) |
| MULTILABEL group | TargetGroupSpec(type=..., columns=[...]) |
Key is a non-ITEM_ group identifier; each member column is ITEM_-prefixed and binary |
Three estimator families, one scorer:
| Family | Class | When to pick |
|---|---|---|
| Joint MLP | JointMultiTargetMLPEstimator |
Shared feature encoder + per-target heads. Default; good baseline when targets are correlated. |
| Joint Transformer | JointMultiTargetTransformerEstimator |
FT-Transformer-style feature tokenization + CLS pooling. Better when pairwise feature interactions matter. |
| Independent | IndependentMultiTargetEstimator |
One scikit-rec sub-estimator per target (XGB, LightGBM, LogReg, sklearn). Use when targets are independent OR you want per-target estimator-type flexibility. Loses the multilabel-group inductive bias. |
All three implement the MultiTargetEstimator Protocol; the scorer accepts any.
Output column conventions:
score_items (wide DataFrame, one row per user, no USER_ID column):
| Target type | Output columns |
|---|---|
| BINARY | ITEM_<col>_0, ITEM_<col>_1 |
| REGRESSION | ITEM_<col> (de-normalized) |
| MULTICLASS | ITEM_<col>_<class_label> per class |
| MULTILABEL | ITEM_<member>_0, ITEM_<member>_1 per member |
predict_targets (one column per fanned-out target):
| Target type | Output column |
|---|---|
| BINARY | ITEM_<col> (predicted label 0/1) |
| REGRESSION | ITEM_<col> (predicted value) |
| MULTICLASS | ITEM_<col> (predicted class label; original dtype preserved) |
| MULTILABEL | ITEM_<member> (predicted label 0/1) per member |
Evaluation (always returns Dict[str, float]):
Heterogeneous target types have no honest macro aggregation. Per-TargetType metric dispatch:
| Target type | Compatible metrics |
|---|---|
| BINARY / MULTILABEL member | ROC_AUC, PR_AUC |
| REGRESSION | RMSE, MAE |
| MULTICLASS | MULTICLASS_ACCURACY (new v2 metric) |
result = recommender.evaluate(
eval_type=RecommenderEvaluatorType.SIMPLE,
metric_type={
"ITEM_clicked": RecommenderMetricType.ROC_AUC,
"ITEM_revenue": RecommenderMetricType.RMSE,
"ITEM_action": RecommenderMetricType.MULTICLASS_ACCURACY,
"ITEM_email_open": RecommenderMetricType.ROC_AUC,
"ITEM_app_open": RecommenderMetricType.ROC_AUC,
},
eval_top_k=10,
score_items_kwargs={"interactions": valid_df},
eval_kwargs={"logged_rewards": valid_targets_wide},
)
# → {"ITEM_clicked": 0.83, "ITEM_revenue": 12.7, "ITEM_action": 0.71, ...}
For metrics outside the named set (log-loss, macro-F1, business metrics), use the score_per_target escape hatch with sklearn callables:
from sklearn.metrics import log_loss, f1_score
metrics = scorer.score_per_target(
interactions=valid_df,
y_true=valid_targets_wide,
metric_callables={
TargetType.BINARY: lambda y, p: log_loss(y, p[:, 1]),
TargetType.MULTICLASS: lambda y, p: f1_score(y, p.argmax(axis=1), average="macro"),
"ITEM_revenue": lambda y, p: float(np.mean((p - y) ** 2)), # name override
},
)
Restricted to RecommenderEvaluatorType.SIMPLE (counterfactual evaluators assume a long-format ranking shape that doesn't apply). Ranking metrics are rejected with a pointer to score_per_target and predict_targets.
Factory config:
config = {
"recommender_type": "ranking",
"scorer_type": "mixed_type_multi_target",
"scorer_config": {"target_specs": target_specs},
"estimator_config": {
"ml_task": "multi_target",
"multi_target": {
"mode": "joint_mlp", # or joint_transformer, independent
"params": {"hidden_dim": 128, "num_layers": 3, "epochs": 10},
},
},
}
recommender = create_recommender_pipeline(config)
For mode="independent", supply per-type defaults and optional per-target overrides:
"multi_target": {
"mode": "independent",
"independent": {
"defaults": {
"binary": {"estimator_type": "xgboost", "params": {"n_estimators": 100}},
"regression": {"estimator_type": "lightgbm", "params": {"n_estimators": 200}},
"multiclass": {"estimator_type": "lightgbm", "params": {}},
"multilabel": {"estimator_type": "xgboost", "params": {}}, # per-member
},
"per_target": {
"ITEM_revenue": {"estimator_type": "lightgbm", "params": {"n_estimators": 500}},
"ITEM_email_open": {"estimator_type": "logreg", "params": {"max_iter": 200}},
},
},
},
Compatible sub-estimator types per declared target type (also published in capability_matrix()["independent_target_compat"]):
| Target type | Sub-estimator types |
|---|---|
| BINARY | xgboost, lightgbm, logreg, sklearn |
| REGRESSION | xgboost, lightgbm, sklearn |
| MULTICLASS | lightgbm, logreg (xgboost excluded — inplace_predict has a multiclass shape bug) |
| MULTILABEL (per member) | xgboost, lightgbm, logreg, sklearn |
Dataset Requirements: - ⚠️ Interactions: One row per user; declared target columns + feature columns - ❌ Users: Not allowed - ❌ Items: Not allowed
Real-time-label conditioning (v3)¶
For scenarios where the caller has observed the ground truth for some targets at inference time (e.g. a real-time event arrived) and wants those values to condition predictions for the remaining targets, use a conditional estimator paired with OBSERVED_<suffix> columns:
from skrec.estimator.classification import (
ConditionalJointMultiTargetMLPEstimator,
)
estimator = ConditionalJointMultiTargetMLPEstimator(
target_specs=target_specs,
params={"epochs": 10, "mask_prob": 0.5, "label_embedding_dim": 8},
)
estimator.fit(X_train, y_train)
scorer = MixedTypeMultiTargetScorer(estimator=estimator, target_specs=target_specs)
At inference, add OBSERVED_<suffix> columns matching declared ITEM_<suffix> targets:
inference_df = pd.DataFrame({
"USER_ID": ["u1"],
"feat_0": [0.5], "feat_1": [-0.3],
"OBSERVED_clicked": [1.0], # observed for this row
"OBSERVED_revenue": [np.nan], # not observed; predict from features
"OBSERVED_action": [np.nan],
"OBSERVED_email_open": [np.nan], # multilabel group members must mask together
"OBSERVED_app_open": [np.nan],
})
predictions = scorer.predict_targets(interactions=inference_df)
OBSERVED_* semantics:
- Vanilla estimators (
JointMultiTargetMLPEstimator,JointMultiTargetTransformerEstimator,IndependentMultiTargetEstimator) reject anyOBSERVED_*column with a clean error pointing at the conditional families. - Conditional estimators permit them. NaN per cell means "not observed for this row, predict from features." Multilabel group members must mask together per row (all observed or all NaN); partial-group observation raises an explicit error.
OBSERVED_*columns are auto-preserved throughinteractions_schema.apply()even when the client schema doesn't declare them, via theBaseScorer.preserved_inference_columns()hook — sorecommend_onlineworks without per-deployment schema changes.
Available in v3. Independent + conditional is NOT supported (cross-target observed-as-features is structurally different; revisited in v4+ if ever).
Compared to MultioutputScorer:
MultioutputScorer |
MixedTypeMultiTargetScorer |
|
|---|---|---|
| Target type | All binary OR all continuous | Heterogeneous per target |
Output of evaluate() |
float (macro) or Dict[str, float] via per_label=True |
Dict[str, float] only |
| Multiclass support | ❌ (3+ class targets rejected) | ✅ |
| Multilabel groups (joint loss) | ❌ | ✅ via TargetGroupSpec |
| Estimator pluralism | Single MultiOutputClassifier/MultiOutputRegressor |
Joint MLP / joint Transformer / independent (any combination) |
When to use: heterogeneous target types in one model (e.g., predict clicks AND revenue AND user-tier-class in one frame); deep tabular models on multi-target data; per-target estimator type flexibility (independent mode).
See also: Decision rule for the full joint-vs-independent / mixed-type-vs-multioutput tree.
6. SequentialScorer¶
How it works: Wraps a SequentialEstimator (SASRec) that scores all items from a user's interaction sequence in a single forward pass.
from skrec.scorer.sequential import SequentialScorer
scorer = SequentialScorer(estimator) # estimator must be a SequentialEstimator
Dataset Requirements:
- ✅ Interactions: Multiple rows per user with TIMESTAMP column
- ❌ Users: Not used (sequences encode user preferences)
- ✅ Items: Used for item vocabulary
- 📊 Outcome: Binary
When to use: When interaction order matters and you want to model sequential patterns (e.g., "users who watched A then B tend to watch C next"). Requires SequentialRecommender and a SASRec estimator. See SASRec guide.
7. HierarchicalScorer¶
How it works: Wraps a SequentialEstimator (HRNN) that models session-structured interaction histories with a two-level GRU hierarchy.
from skrec.scorer.hierarchical import HierarchicalScorer
scorer = HierarchicalScorer(estimator) # estimator must be a SequentialEstimator
Dataset Requirements:
- ✅ Interactions: Multiple rows per user with TIMESTAMP (and optionally SESSION_ID)
- ❌ Users: Not used
- ✅ Items: Used for item vocabulary
- 📊 Outcome: Binary
When to use: When users have distinct browsing sessions and cross-session context matters. Requires HierarchicalSequentialRecommender and an HRNN estimator. See HRNN guide.
Decision Guide¶
graph TD
A[Start] --> Z{Sequential/<br/>session data?}
Z -->|Yes, flat sequences| SEQ[SequentialScorer<br/>+ SASRec]
Z -->|Yes, sessions| HIER[HierarchicalScorer<br/>+ HRNN]
Z -->|No| B{Have item<br/>features?}
B -->|Yes| C[UniversalScorer]
B -->|No| D{One positive<br/>item per user?}
D -->|Yes| E{Need features?}
E -->|No| F[MulticlassScorer]
E -->|Yes| G[Can't use features<br/>with Multiclass.<br/>Use Universal]
D -->|No| H{Multiple binary<br/>outcomes per user?}
H -->|Yes, all binary| I[MultioutputScorer<br/>classifier or regressor mode<br/>binary targets only]
H -->|No| J[IndependentScorer]
Estimator Compatibility¶
Binary Classification Estimators¶
Compatible with scorers when outcomes are binary (0/1): - UniversalScorer ✅ - IndependentScorer ✅ - MulticlassScorer ✅ - MultioutputScorer ✅
Regression Estimators¶
Compatible with scorers when outcomes are continuous:
- UniversalScorer ✅
- IndependentScorer ✅
- MulticlassScorer ❌
- MultioutputScorer ✅ (regressor mode — pair with MultiOutputRegressorEstimator for multi-target regression)
Multiclass Classification Estimators¶
- MulticlassScorer ✅
- Others ❌
Embedding Estimators (MF, NCF, TwoTower, DCN, NeuralFactorization)¶
- UniversalScorer ✅ (auto-dispatches to embedding pipeline)
- IndependentScorer ❌
- MulticlassScorer ❌
- MultioutputScorer ❌
Sequential Estimators (SASRec, HRNN)¶
- SequentialScorer ✅ (for SASRec)
- HierarchicalScorer ✅ (for HRNN)
- All other scorers ❌
Complete Examples¶
Example 1: Universal Scorer (E-commerce)¶
from skrec.scorer.universal import UniversalScorer
from skrec.estimator.classification.xgb_classifier import XGBClassifierEstimator
# Have item features (price, category, brand)
estimator = XGBClassifierEstimator({"learning_rate": 0.1})
scorer = UniversalScorer(estimator)
Example 2: Independent Scorer (Content Recommendation)¶
from skrec.scorer.independent import IndependentScorer
from skrec.estimator.classification.lightgbm_classifier import LightGBMClassifierEstimator
# No item features, each content piece is unique
estimator = LightGBMClassifierEstimator({"learning_rate": 0.05})
scorer = IndependentScorer(estimator)
# Enable parallel inference for speed
scorer.set_parallel_inference(parallel_inference_status=True, num_cores=4)
Example 3: Multiclass Scorer (Simple Ranking)¶
from skrec.scorer.multiclass import MulticlassScorer
from skrec.estimator.classification.xgb_classifier import XGBClassifierEstimator
# Simple setup: one item per user, no features
estimator = XGBClassifierEstimator({"objective": "multi:softmax"})
scorer = MulticlassScorer(estimator)
Example 4a: Multioutput Scorer (Multi-label binary classification)¶
from xgboost import XGBClassifier
from skrec.scorer.multioutput import MultioutputScorer
from skrec.estimator.classification.multioutput_classifier import MultiOutputClassifierEstimator
# Multi-label classification: predict adoption probability for each binary target
estimator = MultiOutputClassifierEstimator(XGBClassifier, params={})
scorer = MultioutputScorer(estimator)
Example 4b: Multioutput Scorer (Multi-target regression)¶
from xgboost import XGBRegressor
from skrec.scorer.multioutput import MultioutputScorer
from skrec.estimator.regression.multioutput_regressor import MultiOutputRegressorEstimator
# Multi-target regression: predict continuous values per target (e.g. revenue, clicks, minutes)
estimator = MultiOutputRegressorEstimator(XGBRegressor, params={})
scorer = MultioutputScorer(estimator)
Best Practices¶
1. Start with UniversalScorer¶
- Best performance in most scenarios
- Leverages item features for better predictions
- Only switch if you have constraints
2. Feature Engineering¶
- UniversalScorer benefits greatly from good item features
- IndependentScorer relies entirely on user-context features
3. Data Volume¶
- UniversalScorer: Needs sufficient data across items
- IndependentScorer: Needs sufficient data per item
- MulticlassScorer: Needs balanced classes
- MultioutputScorer: Needs data for all
ITEM_<name>columns; binary-only in classifier mode (multi-class targets rejected at fit time — see Migration paths for multi-class targets). Single-class-in-train degenerate targets handled per theon_degenerate_targetpolicy (RAISEdefault;CONSTANTto fall back to a constant predictor)
4. Performance Optimization¶
- UniversalScorer: Fast inference (one model call); supports
score_fast()for single-user real-time serving - IndependentScorer: Use
set_parallel_inference()for speed; supportsscore_fast() - MulticlassScorer: Fastest (single prediction); supports
score_fast() - MultioutputScorer: Moderate (one prediction, multiple outputs); supports
score_fast()
All non-embedding scorers support scorer.score_fast(features_df) for low-latency
single-user inference. For end-to-end real-time serving (schema validation + ranking),
use recommender.recommend_online() instead.
Common Issues¶
Issue: "Items dataset required for Universal scorer"¶
Solution: Universal scorer needs item features. Provide items_ds or switch to Independent scorer.
Issue: "Expected one row per user"¶
Solution: Multiclass and Multioutput scorers require one row per user. Aggregate your data or use Universal/Independent scorer.
Issue: Independent scorer is slow¶
Solution: Enable parallel inference:
Next Steps¶
- Estimator Guide - Choose the right estimator for your scorer
- Architecture Overview - Understand how scorers fit in the system
- Training Guide - Train your scorer